The Problem
The tech talent war is intensifying. Sign-on bonuses at AI labs now exceed $1-2M for top researchers. The global developer shortage is projected to reach 85 million workers by 2030. Time-to-hire for senior engineers averages 49 days - and companies lose top candidates to competitors during those lengthy processes.
The sourcing problem sits at the heart of this. GitHub hosts the world's largest collection of developer work samples, but there's no efficient way to search it. Recruiters manually scroll through profiles, trying to assess candidates from scattered signals - contribution graphs, pinned repos, commit histories. The information exists, but extracting it takes 15-20 minutes per profile.
Problem Analysis
This project started at a hackathon focused on the tech recruiting crisis. Before building, we mapped out the core pain points in the sourcing workflow:
- Discovery gap: GitHub search returns usernames, not qualified candidates. There's no way to query "Rust developers in Sydney who contribute to infrastructure projects" - you just get keyword matches.
- Signal extraction: The real indicators of engineering quality - merged PRs to popular projects, code review patterns, collaboration networks - require manual investigation. Pinned repos and star counts are often misleading.
- Context collapse: A green contribution graph shows activity, but not quality. 1,000 commits to personal toy projects means something different than 50 merged PRs to React or Kubernetes.
- Credential inflation: 73% of recruiters say finding qualified tech talent is their biggest challenge - separating genuine skill from inflated credentials requires looking at actual work output.
Requirements
Given we had 48 hours, we scoped to three things:
Semantic Search Over Developers
Enable natural language queries that understand intent. "TypeScript developers who contribute to testing frameworks" should return ranked results, not keyword matches.
Automated Signal Extraction
Transform 20 minutes of manual profile review into instant analysis. Surface language proficiency, contribution quality, collaboration patterns, and activity trends automatically.
Quality-Weighted Scoring
Move beyond vanity metrics. Weight maintained projects over abandoned ones, external contributions over self-owned repos, recent activity over historical.
How it works
The idea: treat GitHub like a database of developer signals. Contribution graphs, language distribution, commit patterns, PR review activity, collaboration networks - there's a lot of structured data buried in profiles that's tedious to extract manually.
Git Radar indexes this data and exposes it through a semantic search layer. Query "Rust developers in Sydney with open source contributions" and get ranked results with profile breakdowns, not a list of usernames.
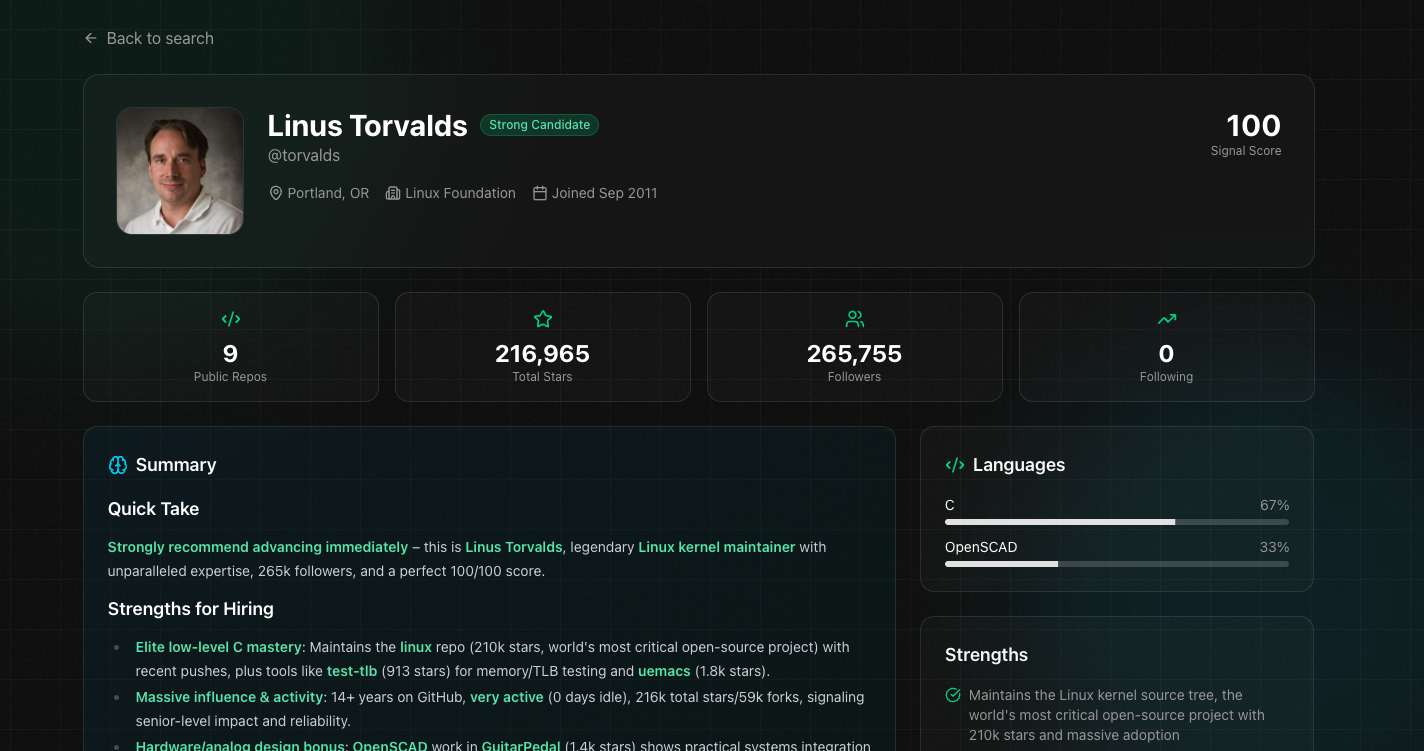
System Design
The indexing pipeline fetches profile data through the GitHub API, extracts features (repos, commits, PRs, languages, collaborators), and stores structured embeddings in PostgreSQL with pgvector. The semantic search layer uses Exa for query understanding, which handles the translation from natural language to vector similarity search.
Profile analysis runs through a dual-model setup: Claude handles the structured extraction (skill classification, experience level inference, contribution quality scoring) while Grok powers the more generative features. The Vercel AI SDK abstracts the model switching - same interface, different capabilities depending on the task.
The collaboration graph visualization was the most interesting frontend problem. D3's force simulation handles the physics, but I wrapped it with React Flow for the interaction layer - pan, zoom, node selection, edge highlighting. The tricky part was tuning the force parameters to produce readable layouts across different network densities without manual positioning.
Implementation Notes
GitHub's API rate limits (5,000 requests/hour authenticated) meant the indexing pipeline needed to be async and resumable. I implemented a job queue with Upstash Redis that handles backpressure automatically - when we hit rate limits, jobs get rescheduled with exponential backoff. The queue also deduplicates requests, so fetching the same profile twice within the cache window is a no-op.
For the LLM integration, I use Zod schemas with the AI SDK's structured output mode. The model returns typed objects that match the frontend's expected shape, which eliminates the parsing/validation layer I'd otherwise need. When the schema changes, TypeScript catches the mismatch at build time rather than runtime.
The Signal Score algorithm weights recent activity higher than historical, with decay curves that differ by contribution type. A merged PR from last month matters more than one from three years ago, but a maintained project with consistent commits over years scores higher than a burst of activity followed by abandonment. The weights were tuned against manual rankings of ~200 profiles.
The Data Pipeline
GitHub's REST API gives you a lot of data, but it's spread across dozens of endpoints and rate-limited to 5,000 requests per hour. For a single profile, we needed to hit 5-10 endpoints - profile info, repos, language breakdowns, commit history, and recent activity. The rate limit math didn't look great, so we built a queue with backpressure - requests get batched, rate limits are tracked, and when we're close to the limit, the queue pauses and resumes after the reset window.
The indexing pipeline transforms raw GitHub data into a structured profile document with languages, top repos, activity scores, and contribution scores. The key piece is the embedding - we concatenated the profile bio, repo descriptions, README snippets from pinned repos, and a sample of recent commit messages into a single text blob, then ran it through an embedding model. This vector captures the semantic meaning of a developer's work in a format that supports similarity search.
Search & Ranking
With profiles indexed and embedded, search was conceptually simple: embed the query, find the most similar profile vectors using pgvector's cosine distance, return the top results. But raw vector similarity wasn't enough. A query like "active React developers" should penalise profiles that haven't committed in months, even if their historical work is relevant.
We needed a composite score weighting multiple signals: semantic similarity, activity recency with exponential decay, repository quality (stars, forks, responsiveness), contribution diversity (external PRs score higher than self-owned work), and consistency (regular commits over time beat burst-and-abandon patterns).
The initial vector search was fast but blunt, so we added a cross-encoder reranker as a second pass. After pgvector returned the top 50 candidates, the reranker scored each query-profile pair together rather than comparing pre-computed embeddings independently. It caught things the embedding search missed - like a profile whose repos were highly relevant but whose bio was generic, or queries with negation that cosine similarity couldn't handle. It added about 200ms per search. Worth it.
Then we added AI-generated summaries. For each result, we sent the query and profile data to Claude and asked for a 2-3 sentence explanation of why this developer might be a good match. The "be honest" instruction in the prompt was important - without it, the model would find tenuous connections to justify every result. With it, lower-ranked results got hedging language that made the results feel trustworthy.
Tech Stack
Frontend
- Next.js 16, React 19
- Tailwind CSS v4
- D3.js, React Flow
Backend
- PostgreSQL, pgvector, Drizzle
- Upstash Redis
- Supabase Auth
AI
- Claude, Grok
- Vercel AI SDK
- Exa Search
Infrastructure
- Vercel
- GitHub OAuth
Retrospective
We spent the first two hours arguing about scope, which turned out to be the most valuable time investment of the entire project. The initial idea was ambitious: real-time GitHub crawling, a recommendation engine, collaborative shortlists, ATS integration. We cut all of it. The scoped version: a search box, ranked results with AI-generated summaries, and a detail view. No user accounts, no saved searches, no fancy filters. Just the core loop - search, browse, understand.
Deploying to Vercel in the first few hours meant every subsequent change was tested in production. We caught CORS issues, environment variable problems, and cold start timeouts early instead of at hour 47. Parallel work also helped - I handled the backend while my teammate owned the frontend. Merge conflicts: zero.
Looking back, error handling should have been part of the first iteration, not the last. We treated it as a polish task and nearly paid for it when we burned through our GitHub rate limits during testing - the app just broke with no fallback. A set of pre-indexed demo profiles would have been cheap insurance for the presentation.
The biggest lesson: AI features are easy to demo and hard to make reliable. The semantic search worked great for common queries but fell apart on edge cases. The summaries were usually good but occasionally hallucinated. The ranking was reasonable but not always intuitive. If I were building this as a real product, I'd spend 80% of my time on the reliability work we skipped entirely. But as a proof of concept, 48 hours was enough to build something genuinely useful.